
First AI Software Engineer 🤖
PLUS: AI agent that can train models by itself, GPT-4.5 Turbo will be here soon (probably in July), Meta's AI infra for Llama-3 training

Today’s top AI Highlights:
Leaked details on GPT 4.5 Turbo, it might be here soon
Autonomous AI agent that can train AI models on its own
Cohere released Command-R for RAG and Tool Use at production-scale
Meta’s Massive AI Hardware Expansion with Dual 24K GPU Clusters
& so much more!
Read time: 3 mins
Latest Developments 🌍
GPT 4.5 Turbo Might be Here Sooner Thank You Think 💃
It seems the OpenAI team accidentally revealed some interesting details on GPT 4.5. Indexed on DuckDuck Go and Bing, the following details from the official blog (which shows error 404) have been leaked:
GPT-4.5 Turbo boasts an impressive context window of 256k tokens, twice as large as GPT-4’s (128k tokens).
The model’s knowledge is up-to-date until June 2024.
GPT-4.5 Turbo is OpenAl’s fastest, most accurate, and most scalable LLM to date.
The search results are no longer available. But we have a sneak peek for you!

The first AI software engineer 🤖
Imagine having an AI that not only does engineering tasks but also continuously evolves like a human software engineer. Introducing Devin, the world's first fully autonomous AI software engineer, designed to work alongside human engineers or independently. What makes Devin stand out is not just its ability to perform complex engineering duties but also its capability to learn from feedback and collaborate on design choices in real time.
Key Highlights:
Devin can plan and execute highly complex engineering tasks that involve thousands of decisions. Beyond just recalling relevant context at every step, Devin learns over time and can autonomously fix its mistakes.
Devin isn’t limited by its initial programming. It can learn and adapt to new technologies.
Devin can seamlessly integrate into existing projects, contributing to mature production repositories with the same proficiency as a human engineer.
It actively collaborates with users. Devin not only reports on its progress in real time but also accepts feedback and adapts its approach accordingly. This ensures that Devin can work through design choices alongside engineers.
On the SWE-bench coding benchmark, a challenging test involving real-world GitHub issues from open-source projects like Django and scikit-learn, Devin resolved 13.86% of the issues end-to-end. This performance far exceeds the previous state-of-the-art, which stood at just 1.96%.
Devin has also aced engineering interviews at leading AI firms, trained and fine-tuned AI models with minimal input, built and deployed end-to-end applications, completed actual projects on Upwork with its unique abilities to autonomously navigate through shell, code editor, and web browser, and much more!
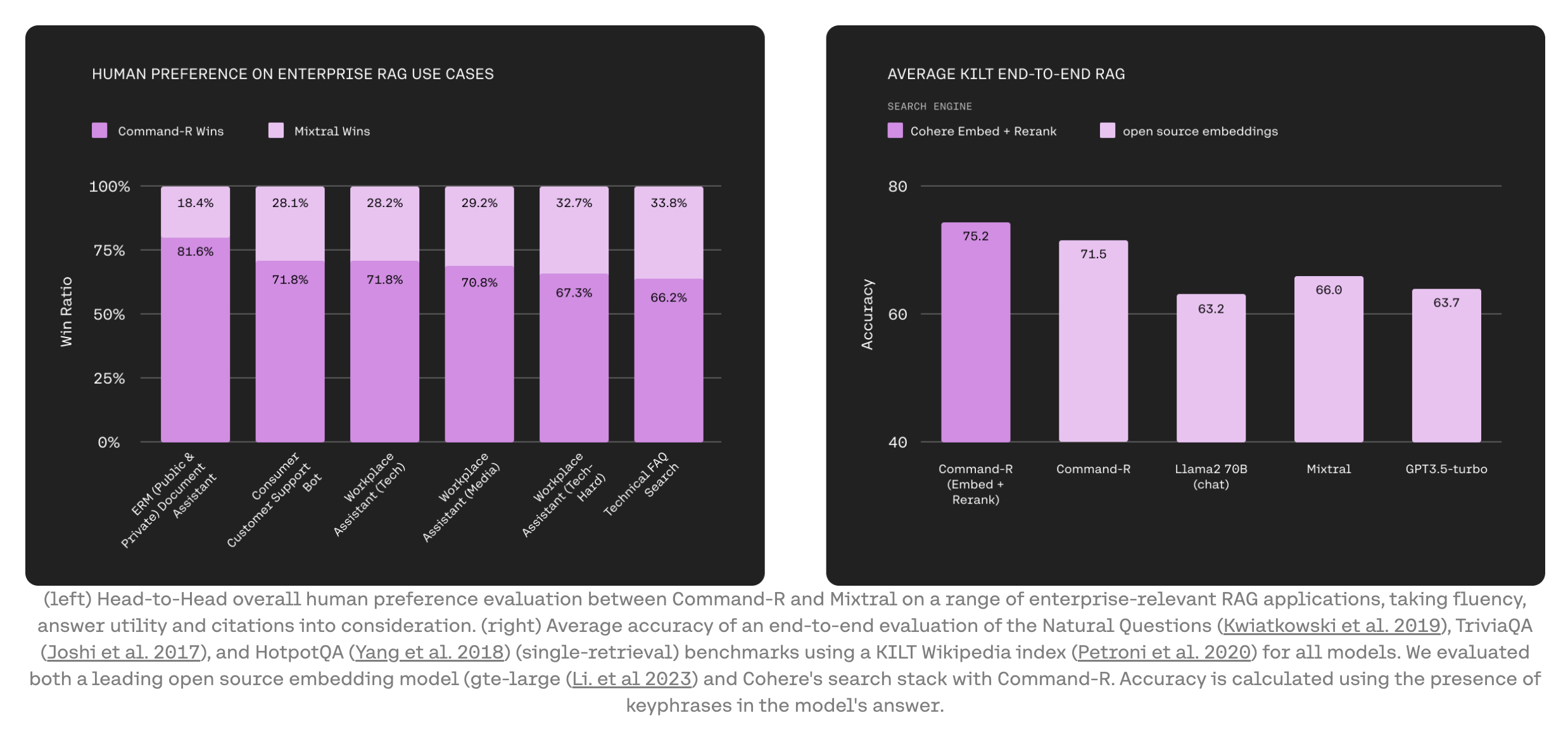
RAG at Scale with Cohere’s New Model 📈
Cohere has just rolled out Command-R, a generative model optimized for long context tasks such as RAG and using external APIs and tools. It caters to the needs of enterprises looking to scale their AI capabilities. This new addition targets the sweet spot between efficiency and accuracy for smoother transitions from prototypes to full-scale production environments. Command-R brings several impressive features and a massive context length.
Key Highlights:
Command-R is built to meet the needs of enterprise-scale applications, with a context window of 128k tokens, low latency, and high throughput. This model is fine-tuned to deliver both efficiency and accuracy.
For RAG, Command-R works alongside Cohere’s Embed (for better contextual and semantic understanding across vast corpora) and Rerank models (for optimized retrieval, using the most relevant information for productive outputs and citing sources to mitigate hallucination risks).
Command-R enables automation of complex tasks and workflows by using internal and external APIs and tools. This allows developers to leverage Command-R for even automating operations that require intricate reasoning or span multiple systems.
It supports 10 key global languages including English, French, and Spanish, making it highly versatile for international use. Further bolstered by Cohere's Embed and Rerank models supporting over 100 languages, it ensures users can access clear and accurate dialogues in their preferred languages.
Command-R excels in various benchmarks, including 3-shot multi-hop REACT and "Needles in a Haystack". When combined with Cohere’s models, it outperforms other scalable generative models in accuracy.
Twin GPU Clusters for Llama 3 🦾
Organizations are increasingly investing in hardware to meet the growing needs of AI research. Just a couple of days we heard of the Indian government investing in a 10,00 GPUs cluster, and now it is Meta. Meta has unveiled two powerful clusters, each boasting 24,576 GPUs, for the current and next-gen models, including Llama 3. By the end of 2024, Meta plans to scale up its arsenal to 350,000 NVIDIA H100 GPUs as part of a portfolio that will feature compute power equivalent to nearly 600,000 H100s.
Following are very technical details on the clusters:
The clusters are built on Meta’s designed Grand Teton, a GPU-based hardware platform that enables the creation of new, specialized clusters tailored for specific applications.
To ensure that these clusters operate without a hitch, Meta has implemented cutting-edge networking solutions. One cluster utilizes RDMA over converged Ethernet (RoCE) for its network fabric, while the other employs the NVIDIA Quantum2 InfiniBand fabric, both designed to handle 400 Gbps endpoints.
Meta has innovated with a dual storage approach. A custom Linux Filesystem in Userspace (FUSE) API, backed by Meta’s Tectonic distributed storage, caters to the data-heavy demands of AI training. Also, a partnership with Hammerspace introduces a parallel network file system to streamline data handling.
Prioritizing performance and ease of use, Meta has managed to significantly improve large cluster performance through software and network optimizations, including tailored job scheduling and routing strategies.

Tools of the Trade ⚒️
Ragas: An open-source infrastructure designed for evaluating and testing LLM applications. It employs model-graded evaluations and testing techniques, including automated test data synthesis, explainable metrics, and adversarial testing, and has become the default standard for evaluating RAG applications.
Agentboard: The easiest and fastest way to use AI agents. This platform is designed to make using AI agents for various tasks, such as code execution, CSV analysis, and file conversion, easy and accessible via a web browser, without the need for complex setup processes.
Enchanted: An open-source application for iOS and macOS for chatting with private, self-hosted language models such as Llama2, Mistral, or Vicuna using Ollama. It provides an unfiltered, secure, private, and multimodal experience across the iOS ecosystem.
😍 Enjoying so far, TWEET NOW to share with your friends!
Hot Takes 🔥
Everyone is piling on Google, but I am personally impressed: it’s rare to see a company of that size testing in production these days. ~
Respectfully, AI today is not like atomic science before the Manhattan project. The problem is there's a terrible Wizard of Oz effect. Even smart people who understand LLMs intellectually get fooled by the seeming intelligence of ChatGPT etc. Smooth text interpolation + a giant text database + convnets++ is roughly GPT4V. Note no planning or reasoning. There is no intent or goal setting but rather just the extraordinary capability of transformers to compress and query text and image data.
Very cool stuff, but it sounds much sillier to compare a large database to a nuclear bomb. A lot of the supposed threats of ChatGPT (how to make a bioweapon etc) also hold true for a large queryable database ~
Bharath Ramsundar
Meme of the Day 🤡
What should I do? 😟

That’s all for today!
See you tomorrow with more such AI-filled content. Don’t forget to subscribe and give your feedback below 👇
Real-time AI Updates 🚨
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!!
PS: I curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!