


Windows get AI Music Copilot 🪟
PLUS: GPT-4 Turbo v/s Google's Gemini Pro, Fast LLM Inference on PCs, Prompt Compression for Enhanced Accuracy

Today’s top AI Highlights:
Turn your Ideas into Songs with Suno on Microsoft Copilot
An In-depth Look at Gemini's Language Abilities
High-speed LLM Serving on PCs with Consumer-grade GPUs
Designing a Language for LLMs via Prompt Compression
Pika Introduces the Generative Fill for Videos
& so much more!
Read time: 3 mins
Latest Developments 🌍
Generate Music Using AI Within Copilot 🎶
Microsoft Copilot now lets you generate music with AI using simple text prompts. Microsoft has partnered with Suno, a leading AI music generation company, to let users create music of various genres and styles including the lyrics, from text prompts.
You don't need to know how to sing, play an instrument, or read music. The combination of Microsoft Copilot and Suno will handle the complex parts of music creation. Simply visit the Copilot website, sign in to your Microsoft account, and enable the Suno plugin which is being rolled out already!
.gif")
Gemini vs GPT 4 vs GPT 3.5: Which is the Better Model 🥇
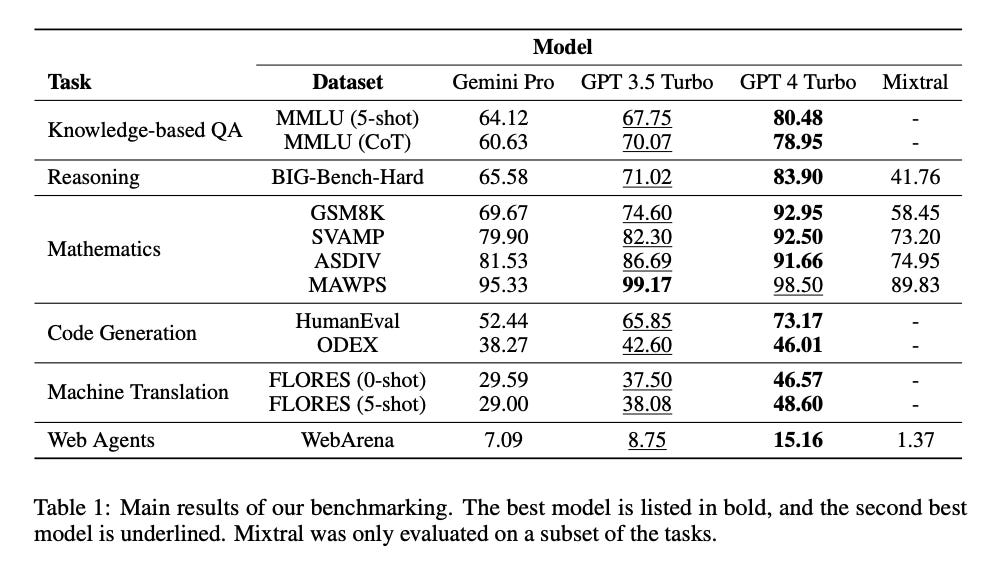
CMU researchers have put Google's latest model, Gemini Pro, under the microscope, comparing its capabilities and performance against OpenAI's GPT series. This analysis was done over 10 datasets testing a variety of language abilities including reasoning, QA, math problems, translation, instruction-following, and coding.
While in most of the tasks, Gemini fell short of GPT-4 and performed closely with GPT 3.5 Turbo, Gemini shines in tasks including non-English languages, and handling longer and more complex reasoning chains.
Key Highlights:
In knowledge-based QA and reasoning tasks, Gemini Pro achieved an accuracy of 64.12% trailing behind GPT 3.5 Turbo (67.75%) and GPT 4 Turbo (70.07%). In general-purpose reasoning tasks, Gemini Pro's performance was slightly lower than GPT 3.5 Turbo and significantly lower compared to GPT 4 Turbo, demonstrating Gemini Pro's relatively weaker performance in complex reasoning and knowledge-based QA scenarios.
In mathematical reasoning tasks, Gemini Pro's accuracy was consistently lower than both GPT models. Similarly, in code generation tasks, Gemini Pro's Pass@1 metric was lower than that of the GPT models, indicating a need for improvement in complex problem-solving and coding capabilities.
The study also included a cost analysis based on the pricing for 1 million tokens. Gemini Pro's input and output costs were $1.00 and $2.00 respectively, in contrast to GPT-3.5 Turbo ($1.00 and $2.00) and GPT-4 ($10.00 and $30.00). Mixtral had the lowest cost at $0.60 for both input and output. This comparison offers an essential perspective on the trade-off between cost and performance.
Bringing High-Speed AI to Consumer-Grade Computers 👩💻
PowerInfer, a new tool for running advanced language models, brings high-speed AI processing to everyday computers with standard GPUs. This tool cleverly combines CPU and GPU capabilities to handle complex language tasks more efficiently, making powerful AI models more accessible for personal use and research.
Key Highlights:
PowerInfer uses a smart blend of CPU and GPU processing, focusing on handling different types of data ('hot' and 'cold' neurons) more effectively. This approach allows it to process information quickly, achieving speeds close to those of high-end server GPUs on standard NVIDIA RTX 4090 GPUs.
PowerInfer achieves an average token generation rate of 13.20 tokens/s and a peak of 29.08 tokens/s across various LLMs on a single NVIDIA RTX 4090 GPU. This performance is only 18% lower than the top-tier A100 GPU. It outperforms llama.cpp by up to 12x while maintaining model accuracy.
Designed for straightforward integration and use, PowerInfer supports a range of popular AI models and can be easily set up on various systems, including Linux-based CPUs and GPUs, as well as Apple's M series chips. It also works with existing setups designed for llama.cpp, making it a versatile choice for various AI tasks.
![[video-to-gif output image]](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F56e4cb4d-5da3-4ce9-afa8-18ab2ad904f4_800x320.gif "[video-to-gif output image]")
Less is More 🎯
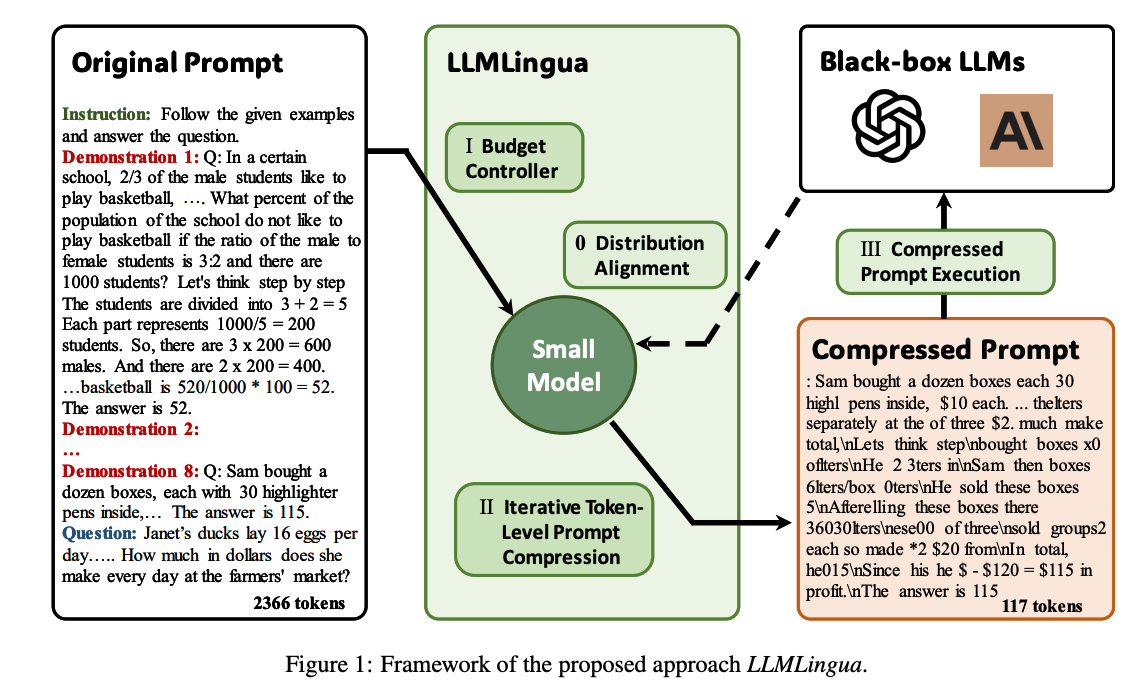
LLMs have been increasingly used in various domains, but their effectiveness is hindered by long prompts, leading to issues like increased API response latency, exceeded context window limits, loss of contextual information, expensive API costs, and performance issues. Researchers at Microsoft have introduced LLMLingua designed for prompt compression up to 20x, to streamline the processing of prompts in LLMs, focusing on enhancing efficiency and accuracy.
Key Highlights:
LLMLingua uses a method that analyzes the natural redundancy present in language and strategically eliminates extraneous elements. By focusing on the core elements of a prompt, LLMLingua compresses it to a more manageable size without losing critical information.
LLMLingua achieves an impressive 20x compression ratio with minimal performance loss. Conversely, LongLLMLingua, with a 4x compression ratio, not only retains efficiency but also shows a notable 17.1% improvement in performance.'
These methods are tested in scenarios like Chain-of-Thought reasoning, long contexts, RAG, online meetings, and code completion. In a RAG test, LongLLMLingua showed a 75.5% accuracy with 4x compression, compared to 54.1% for the original prompt.
The research emphasizes a critical trade-off between language completeness and compression ratio. Notably, it was observed that GPT-4 is capable of recovering all key information from a compressed prompt. The study underlines the importance of thoughtful prompt engineering where the density and position of key information within prompts significantly impact the performance of downstream tasks.
Tools of the Trade ⚒️
Modify Region by Pika Labs: You can now edit a specific part of the video with a text prompt while keeping the remaining portion intact. Just click on “Modify Region'“, adjust the selection box, and edit your prompt, an voila!
![[optimize output image]](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F95d2f92a-c4ef-4f76-92e5-ae06da810c4b_800x450.gif "[optimize output image]")
Calvin: Opensource Google Calendar Assistant that manages Google Calendar tasks, like listing calendars, answering event-related queries, and creating new events. It leverages GPT-4 for decision-making and response generation, and Langchain to provide structured information and function execution based on user interactions.
gptengineer.app: Enables rapid prototyping of web apps using simple prompt, with a workflow that integrates AI and git for easy iteration and deployment.
Any Call Santa: A unique holiday experience through a special live chat with Santa, powered by AI. Just call on the given nuber and give details about your kids to Poppy the Elf, you then call again from the same number and let your kids talk to Santa!
😍 Enjoying so far, TWEET NOW to share with your friends!
Hot Takes 🔥
We should regulate criminal activity but not the underlying AI technology. We would be living in a different world if the internet were regulated. ~ Bindu Reddy
Innovation is easier with small teams making decisive, concentrated bets, who don't tolerate mediocre performers. That's it. ~ Sam Altman (Source)
Meme of the Day 🤡

That’s all for today!
See you tomorrow with more such AI-filled content. Don’t forget to subscribe and give your feedback below 👇
Real-time AI Updates 🚨
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!!
PS: I curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!
Microsoft's partnership with Suno means they're no longer relying purely on OpenAI's models - not sure what it says about their strategy, but an interesting development.