
Did OpenAI release GPT-4.5 in Stealth? 🤫
PLUS: Opensource AI Speech Restoration and Enhancer, 11B Model Tops the HF Leaderboard

Today’s top AI Highlights:
ChatGPT Mentions its API Name as GPT 4.5 Turbo
11B Model Outperforms even 30B Parameter Models
Resemble Enhance: Open Source Speech Super Resolution AI Model
Pixel-Aligned Image Captioning Model
& so much more!
Read time: 3 mins
Latest Developments 🌍
Rumours Around GPT 4.5 Fly Again 💬

A Small 11B Model Tops the HF Open LLM Leaderboard 🏆
Upstage, a leading AI startup from Korea, has released Solar 10.7B, a pre-trained LLM with 10.7 billion parameters. Solar achieved a score of 66 on the leaderboard, ranking it first overall, outperforming larger models including Qwen, Mixtral 8x7B, Yi-34B, Llama 2, and Falcon. Trained on an excellent data from over 3 trillion tokens, the model is a perfect balance of size and performance.
Key Highlights:
The Solar model was developed using an innovative Depth Up-Scaling technique, leveraging the Llama 2 architecture. This approach involved integrating Mistral 7B weights into the upscaled layers, followed by continued pre-training across the model. As a result, Solar demonstrates remarkable performance, outperforming models with up to 30 billion parameters.
Unlike other models, Solar did not use leaderboard benchmarking data sets for pre-learning and fine-tuning but applied its own built data. This approach demonstrates its high usability in general business applications.
The team has also released Solar 10.7B-Instruct Model that is specifically designed for fine-tuning purposes. It achieved a remarkable score of 74.2 on the Hugging Face Open LLM Leaderboard, highlighting its proficiency in executing instruction-based tasks with high accuracy and efficiency.

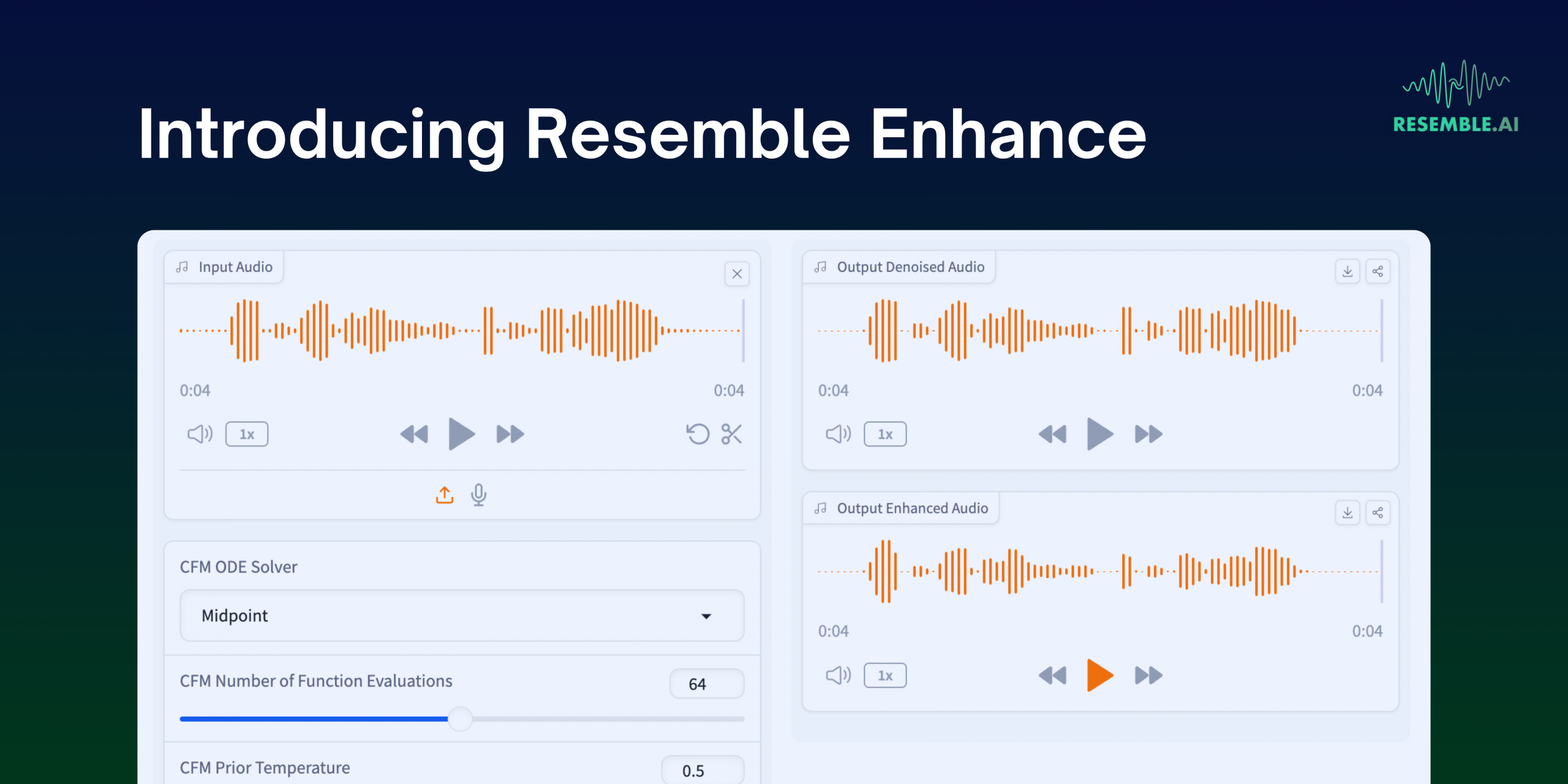
Open Source Speech Super Resolution 🎙️
Crystal clear sounds are very necessary for various purposes like podcasts, entertainment industry, or historic audio restoration. But it been a longstanding challenge due to background noises, recording quality, and other distortions. Resemble AI has introduced Resemble Enhance, an open-source AI model focused on addressing the challenge of achieving pristine sound quality in digital audio. Do listen to the sample audio in the blog, it is impressive!
Key Highlights:
Resemble Enhance features a two-part system: The first part, a denoiser to separate speech from background noise, predicting the magnitude mask and phase rotation. The second part, an enhancer, utilizes a latent conditional flow matching model to enrich audio quality by restoring distortions and extending bandwidth.
The model is trained on 44.1kHz high-quality speech data and utilizes advanced audio processing techniques. These include methods for effectively differentiating between noise and speech, refining audio details, and enhancing sound fidelity.
Resemble AI plans to further refine Enhance to process very old recordings (over 75 years old) more efficiently and to allow more detailed control over speech characteristics.
AI Region-Specific Image Captioning 🏞️
Researchers at Google and UC San Diego have released PixelLLM, a new vision-language model for detailed, region-wise image captioning. This model represents a substantial advance in the ability of AI to interpret and describe images by focusing on specific regions and associating them with accurately generated textual descriptions.
Key Highlights:
PixelLLM generates captions for specific parts of an image. It uses location data (like points or boxes) to focus on particular areas, creating accurate descriptions for those regions. When it's given pixel locations as outputs, the model can identify the exact location of each word it generates, leading to more precise image understanding.
PixelLLM's design includes a prompt encoder, image encoder, and a feature extractor. These components work together to translate image features into text descriptions. The model also uses a special layer (MLP) to link words to their corresponding pixel locations.
It shows top performance in referring localization, location-conditioned captioning, and dense object captioning. This success is evident on challenging datasets such as RefCOCO and Visual Genome. Its flexibility to handle different types of input and output, like locations or text, makes it widely applicable.
![[video-to-gif output image]](https://substackcdn.com/image/fetch/$s_!LCtm!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F109fd4fe-71ef-4fe6-90ab-d72c7c19a296_800x450.gif "[video-to-gif output image]")
Tools of the Trade ⚒️
CamelQA: An AI-powered tool for automated mobile app testing on real phones, focusing on early bug detection and seamless integration into existing development workflows. It offers detailed reporting with video, logs, and reproducible test scripts.
Qashboard: A bird's eye view of your finances. It is a financial management tool that consolidates all your financial accounts for easy analysis, featuring an intuitive dashboard and a ChatGPT-like assistant for financial queries.
Lemonfox.ai: Save upto 75% with Lemonfox’s affordable APIs for speech-to-text, text-to-speech, ChatGPT-like text generation, and AI image creation, emphasizing fast, easy integration and low costs.
Mysports.AI: AI sports prediction platform for over 600 sports features to forecast match results, offering over 75% accurate forecasts for various sports, including NBA, MLB, and top football leagues. It features detailed, real-time analyses and betting recommendations, win/loss line and total runs predictions, and more!
😍 Enjoying so far, TWEET NOW to share with your friends!
Hot Takes 🔥
Imagine if Google had kept Transformers' secret, OpenAI wouldn't even have invented GPT.
It's real shame from OpenAI. ~ Ashutosh ShrivastavaLMs are stochastic *devices* for pattern processing. Like CPUs or GPUs, but Language Processing Units (LPUs). ~ Omar Khattab
Meme of the Day 🤡

That’s all for today!
See you tomorrow with more such AI-filled content. Don’t forget to subscribe and give your feedback below 👇
Real-time AI Updates 🚨
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!!
PS: I curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!
"Solar did not use leaderboard benchmarking data sets for pre-learning and fine-tuning but applied its own built data"
More and more, it seems like inference and even model architecture is becoming commoditized, and the next war is going to be for proprietary datasets.