
Claude 3 surpass GPT-4 in all Benchmarks 🚀
PLUS: ChatGPT can now read, Tenstorrent's first-gen AI card, LLMs forecast with human-level accuracy

Today’s top AI Highlights:
Anthropic releases three models under Claude 3
ChatGPT can now read responses to you
Human-Level Forecasting with Language Models
Tenstorrent releases its first-gen AI card “Grayskull”
Building your own video generation model like OpenAI's Sora
& so much more!
Read time: 3 mins
Latest Developments 🌍
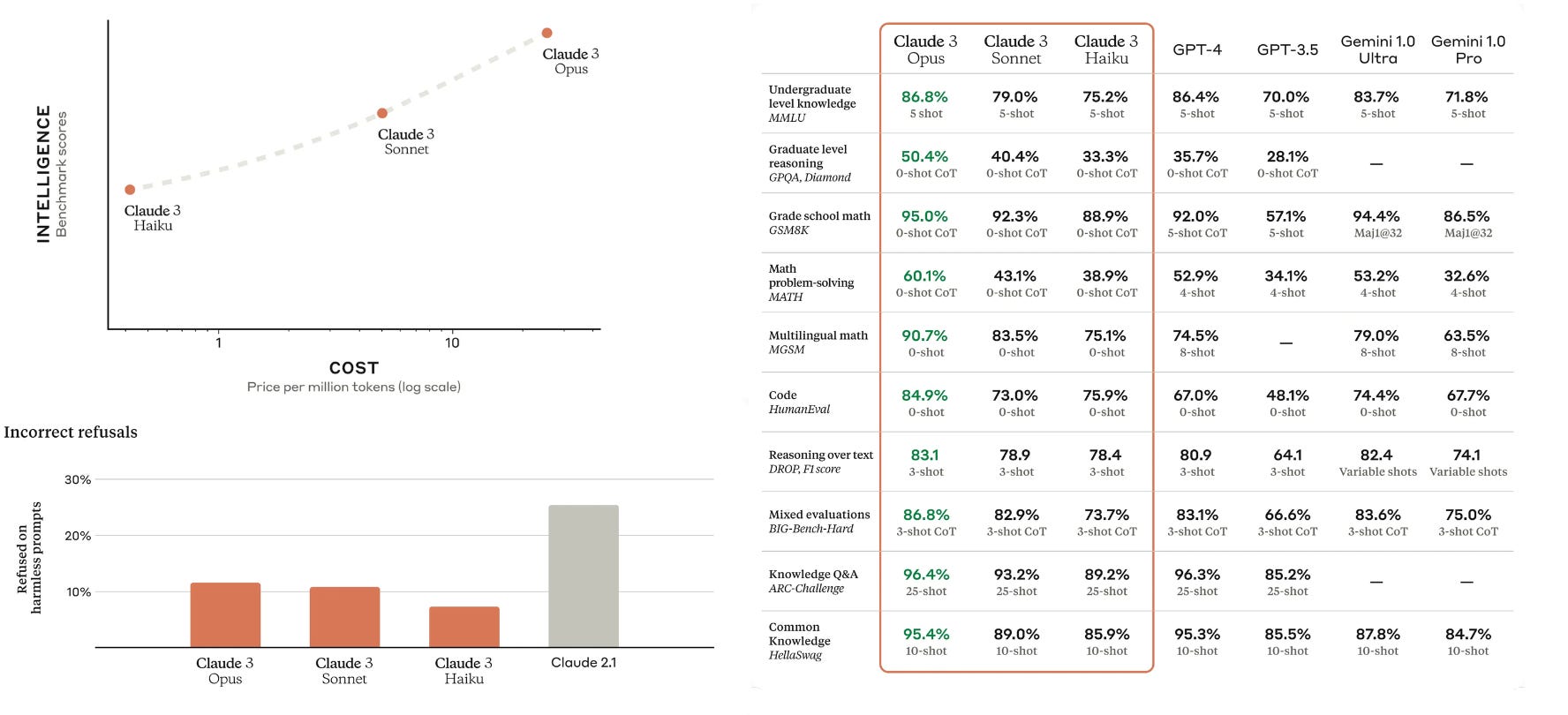
Claude 3 beats GPT-4 in all the benchmarks 🤯
The AI field welcomes Anthropic’s Claude 3 model family, a trio of models designed to cater to a wide spectrum of cognitive tasks. The series includes three models: Haiku for speed and cost efficiency, Sonnet for a balanced approach, and Opus for maximum intelligence. Opus and Sonnet are accessible in 159 countries through the Claude platform and API, with Haiku set to join them shortly.
Here’s everything you have to know:
Claude 3 models excel in reasoning, reading comprehension, math, science, and coding, achieving superior capabilities and state-of-the-art results in these areas. Opus, the most intelligent model, outperforms its peers including GPT-4 and Gemini Ultra on most of the common evaluation benchmarks including MMLU, basic mathematics (GSM8K), math, coding, reasoning, knowledge QA, and HelloSwag.
The models are multimodal, handling a wide range of visual formats, including photos, charts, graphs, and technical diagrams. All three models perform very competitively with GPT-4V and Gemini models.
Haiku breaks new ground in processing speed, capable of analyzing dense research papers on arXiv (~10k tokens) with charts and graphs in under three seconds. The model can power live customer chats, auto-completion tasks where responses must be immediate and in real-time.
Significant improvements have been made in reducing unnecessary refusals, with the new models showing a better understanding of complex prompts and guardrail limitations.
Opus has doubled accuracy relative to Claude 2, in answering complex, open-ended questions compared to its predecessors, reducing incorrect responses.
All three initially offer a 200K token context window, with potential expansion to 1 million tokens, the models cater to applications requiring long-context processing.
Language models typically struggle with recalling information from the middle of long contexts. But Claude 3 Opus demonstrates near-perfect accuracy, consistently achieving over 99% recall in documents up to 200K tokens.
The knowledge cutoff for the Claude 3 models is August 2023.
Claude 3 models have positioned themselves as very tough competitors to GPT-4 in performance. The API pricing is on the slightly higher side where Opus is priced at $15 per million tokens (input) and $75 per million tokens (output), in comparison to GPT-4 Turbo (128k context) $10.00 per million tokens (input) and $30.00 per million tokens (output).
OpenAI won’t Stop Shipping New Features 🔈
OpenAI is rolling out the “Read Aloud” feature which lets you listen to ChatGPT responses. The feature is currently available on the iOS and Android app, and will soon be available on the web. Just tap on ChatGPT’s response and click on Read Aloud to listen to it. You can even change the voice in your Settings > Voice.

Making LMs Forecast at Human-level Accuracy 🔮
The significance of forecasting cannot be emphasized much in any field. The current approaches: statistical and judgemental, require vast amounts of data, excellent domain knowledge, and intuition. How about automating the pipeline using language models? Here’s a retrieval-augmented LM system designed to automatically search for relevant information, generate forecasts, and aggregate predictions. This system competes with, and in some cases surpasses, the forecasting accuracy of human experts.
Key Highlights:
Researchers examined a range of LMs, including GPT-4 and Llama-2, applying a self-supervised fine-tuning approach. The forecasting ability was assessed using a dataset of questions from competitive forecasting platforms.
The system's average Brier score, a measure used to quantify the accuracy of probabilistic predictions, is .179, closely approaching the human crowd aggregate's score of .149. A lower Brier score indicates better forecast accuracy, revealing the system's high level of performance in predicting binary outcomes for future events.
It outperformed human forecasters in a selective setting, where forecasts were made only under specific conditions that played to the system's strengths. These conditions included times when human predictions showed high uncertainty, earlier retrieval dates for information, and when a significant number of relevant articles were available.
An interesting finding was that combining the LM system's forecasts with the human crowd led to improved overall accuracy, lowering the collective Brier score from .149 to .146. This suggests that the LM system can not only stand on its own as a forecasting tool but also significantly enhance human forecasting efforts when used in tandem.

Tenstorrent Launches Grayskull DevKits 🧑💻
Grayskull is Tenstorrent’s first-gen inference-only AI PCIe card that comes with their opensource software stack TT-Metallium. TT-Metalium provides you with open access to Tenstorrent hardware to optimize low-level ops for your AI models.
Stay tuned for an exciting and super rewarding Bounty Program for the GS cards!

Tools of the Trade ⚒️
Open-Sora: Open-source project that offers a comprehensive solution for replicating Sora's development pipeline, featuring Colossal-AI powered data processing, training, and deployment with support for dynamic resolution and multiple model structures. It accommodates various video compression methods and parallel training optimizations.
Risotto: AI-enabled IT help desk solution as a Slack channel to automate IT support tasks. It offers features like 24/7 automated software access and IT support, aiming to improve resolution times, reduce SaaS spend, and enhance security for IT teams.
Small Hours: Automate root cause analysis for production issues, and reduce service downtime, customer impact, and engineering effort. It offers a CLI for developers to deploy an on-call agent that can be integrated with AWS, GCP, or Azure cloud environments, supporting both GPT-4 and open-source LLMs.
😍 Enjoying so far, TWEET NOW to share with your friends!
Hot Takes 🔥
It would be awesome, if Sergey or Larry were the CEO of Google
Google would go back to its roots of not being evil and there would be a vibe shift towards innovation and creativity! ~ Bindu ReddyFeels like the Claude 3 release was strategically timed, knowing that OpenAI probably can’t release a better model later today, given the Elon lawsuit. ~ Matt Shumer
Meme of the Day 🤡

That’s all for today!
See you tomorrow with more such AI-filled content. Don’t forget to subscribe and give your feedback below 👇
Real-time AI Updates 🚨
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!!
PS: I curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!