


Mixtral MoE 8x7B details are out 🔥
Mistral AI released a research paper revealing Mixtral MoE model details

Mixtral 8x7B is a Sparse Mixture of Experts (SMoE) language model that changed the LLM landscape. Developed as an enhancement of the Mistral 7B architecture, Mixtral 8x7B introduces a sophisticated Sparse Mixture of Experts (SMoE) design, setting a new benchmark in the efficiency and capability of language models.
With its unique approach to handling a vast parameter space, Mixtral 8x7B demonstrates notable improvements in performance, particularly in areas such as mathematics, code generation, and multilingual tasks, challenging the existing standards set by models like GPT-3.5 and Llama 2 70B.
The model's fine-tuning for instruction following and its reduced bias in outputs reflect a thoughtful progression towards more ethical and effective AI tools. Its release under the Apache 2.0 license further emphasizes its potential for wide-ranging applications and accessibility in various domains.
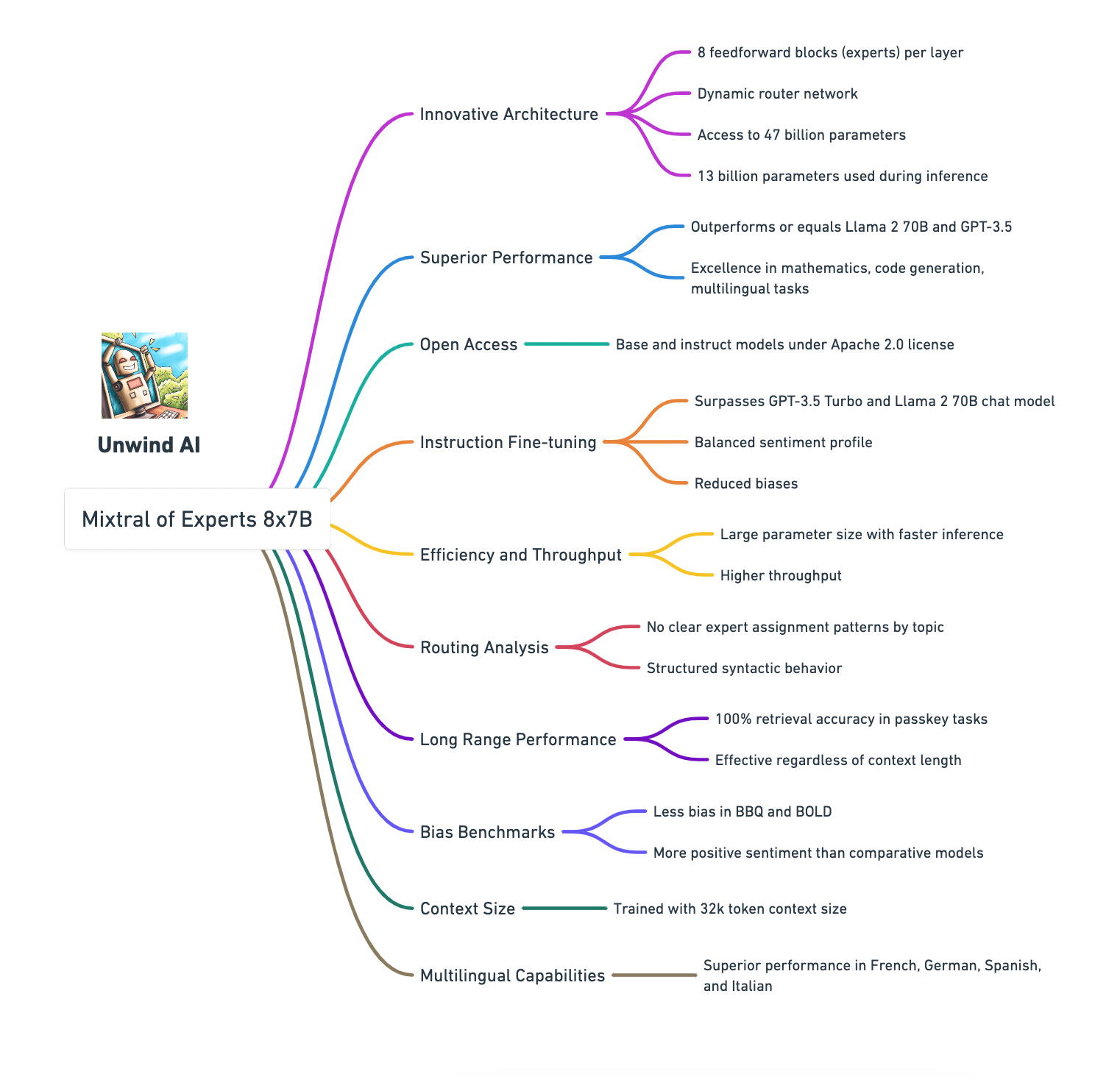
Here's are the key highlights from the research paper 🧵 👇
1. Innovative Architecture: Mixtral consists of 8 feedforward blocks (experts) in each layer. A router network dynamically selects two experts for each token at each layer, allowing access to 47 billion parameters while only actively using 13 billion during inference.
2. Superior Performance: Mixtral outperforms or equals the performance of models like Llama 2 70B and GPT-3.5 in various benchmarks. It shows significant superiority in areas like mathematics, code generation, and multilingual tasks.
3. Open Access: Embracing the spirit of Opensource, Mistral released both the base and instruct models are released under the Apache 2.0 license, ensuring broad accessibility for diverse applications.
4. Instruction Fine-tuning: The Mixtral 8x7B Instruct model, specifically fine-tuned for instruction following, surpasses models like GPT-3.5 Turbo and Llama 2 70B chat model in human benchmarks. It demonstrates a more balanced sentiment profile and reduced biases.
5. Efficiency and Throughput: Despite its large parameter size, Mixtral offers enhanced efficiency with faster inference speeds and higher throughput.
6. Routing Analysis: The paper includes an analysis of the expert selection by the router, revealing no clear patterns of expert assignment based on topic but some structured syntactic behaviour.
7. Long Range Performance: Mixtral demonstrates strong capabilities in handling long context, achieving a 100% retrieval accuracy in passkey retrieval tasks regardless of context length or passkey position.
8. Bias Benchmarks: Performance on Bias Benchmark for QA (BBQ) and Bias in Open-Ended Language Generation Dataset (BOLD) suggests that Mixtral presents less bias and displays more positive sentiment than comparative models.
9. Context Size: Mixtral was trained with a context size of 32k tokens, significantly enhancing its performance in tasks requiring extensive context understanding.
10. Multilingual Capabilities: Mixtral shows significant performance improvement in multilingual understanding, outperforming Llama 2 70B in languages like French, German, Spanish, and Italian.
🔗 For more details, check out the Research paper!
🚨 IMPORTANT
Stay tuned for another week of innovation and discovery as AI continues to evolve at a staggering pace. Don’t miss out on the developments – join us next week for more insights into the AI revolution!
Click on the subscribe button and be part of the future, today!
📣 Spread the Word: Think your friends and colleagues should be in the know? Click the 'Share' button and let them join this exciting adventure into the world of AI. Sharing knowledge is the first step towards innovation!
🔗 Stay Connected: Follow us for updates, sneak peeks, and more. Your journey into the future of AI starts here!
Shubham Saboo - Twitter | LinkedIn ⎸ Unwind AI - Twitter | LinkedIn