


Last Week in AI - A Weekly Unwind
From 13-April-2024 to 19-April-2024


It was yet another thrilling week in the AI field with advancements that further extend the limits of what can be achieved with AI.
Here are 10 AI breakthroughs that you can’t afford to miss 🧵👇

Apple’s New M4 Chip Will Boost AI in Next-Gen Macs 👩💻
Lagging in the AI technology sector compared to companies like Google and Microsoft, Apple is planning to boost AI capabilities in its Mac lineup with the forthcoming M4 chips. The M4 chips will feature enhanced Neural Engine cores for more efficient AI tasks such as voice recognition and image processing, and will also include hardware-accelerated ray tracing and AV1 codec support to improve graphics performance. Additionally, Apple is maintaining its focus on a unified architecture to ensure AI improvements are consistently integrated across all devices.

New AI Wearable to Make Your Day Easier 😌
The creators of the Rewind pendant have launched a new AI wearable, Limitless. Priced at $99, the device captures everything you see, say, and hear, giving your AI a super understanding of your world. Limitless captures and transcribes your conversations, creates real-time notes, and even generates summaries afterward. With a whopping 100-hour battery life, you can wear it all day. It features a “Consent Mode” for privacy, and encrypts data in a “Confidential Cloud,” to ensure your data and conversations are private.
Grok 1.5 is now Multimodal 👀
Just two weeks after releasing Grok 1.5, xAI has introduced the multimodal version of the LLM, Grok 1.5V. The model is capable of processing various visual information including documents, diagrams, and photographs, and will be accessible to Grok users soon. It will allow users to interact with images, generate text from visuals, and derive insights from complex diagrams and charts. xAI has also developed the RealWorldQA benchmark to test the spatial understanding of multimodal models using over 700 real-world images. Grok 1.5V performs competitively with SOTA multimodal models like GPT-4V, Gemini 1.5 Pro, and Claude 3 Sonnet across various tasks.

Adobe Brings Firefly for Video Editing with Text Prompts🪄
Adobe is bringing generative AI for video editing into its Adobe Premiere Pro, powered by Adobe Firefly, to accelerate and simplify video editing. These tools will allow users to add or replace objects, remove unwanted objects, and extend clips in existing videos using straightforward text prompts. Adobe is also collaborating with OpenAI, Pika Labs, and Runway ML to give users the option to select from various AI models within Adobe Premier Pro.
Gemini Models Get a New Competitor 🦾
Reka has launched its most advanced multimodal model, Reka Core, alongside two other models, Reka Edge and Flash, all of which can process text, images, video, and audio. Reka Core, with a context length of up to 128K tokens, matches the performance of leading industry models such as GPT-4, Gemini 1.5, and Claude-3 on various benchmarks, including MMLU and video understanding. The models, trained on a diverse mix of data, cater to different computational needs, with Edge and Flash providing robust options without the bulk of larger models.
Quick Updates from OpenAI 🤌
OpenAI has unveiled several significant updates to enhance developer tools and resource management across its platforms. These improvements focus on introducing a Batch API, streamlining project management through the API dashboard, and expanding capabilities within the Assistants API.
The new Batch API helps developers execute large-scale AI tasks more efficiently by utilizing computational resources during off-peak hours. Users can upload files with multiple queries for asynchronous processing, with a 50% cost reduction during these less busy periods. The outcomes of these tasks are guaranteed within a 24-hour window, optimizing both cost and time.
To better manage development initiatives, OpenAI has also launched “Projects” within its API dashboard. This tool enables project owners to create and manage up to 1000 distinct projects with individualized access and API keys. Each project can have its own tailored permissions and rate limits, providing a structured and secure environment for managing large-scale operations and different development teams.
OpenAI has upgraded its Assistants API to ‘assistants v2,’ which introduces significant improvements in file management and search capabilities. The updated API supports up to 10,000 files per assistant, incorporates vector store objects for automatic file parsing and embedding, and offers advanced search features with multi-threaded execution.
Portraits Come to Life with Lip Sync and Expressions 🙆♀️
Microsoft’s new model VASA-1 technology can transform any portrait photo into a hyper-realistic talking head video synchronized with spoken audio. It captures natural lip movements, facial expressions, and head movements in real-time, enhancing the realism of digital characters for applications such as virtual assistants and entertainment media. The technology also allows users to control various features of the video, such as eye direction and emotional expressions, and supports multiple languages. VASA-1 operates efficiently, generating high-quality videos at 40 frames per second using a single NVIDIA RTX 4090 GPU.
Boston Dynamics Replaces Hydraulic Atlas Robot with New Electric Robot 🦿
Boston Dynamics has discontinued its hydraulic robot Atlas and introduced a new, fully electric version designed for real-world applications. The latest Atlas features a more streamlined design and greater agility, capable of performing complex gymnastic and parkour movements, including a 180-degree flip, with enhanced coordination, balance, and strength. This model includes improvements such as a LiDAR sensor for better navigation and a new gripper for handling diverse objects. Additionally, the transition from hydraulic to electric actuators makes the robot quieter and more energy-efficient, with Boston Dynamics collaborating with Hyundai to test these capabilities in real-world settings.
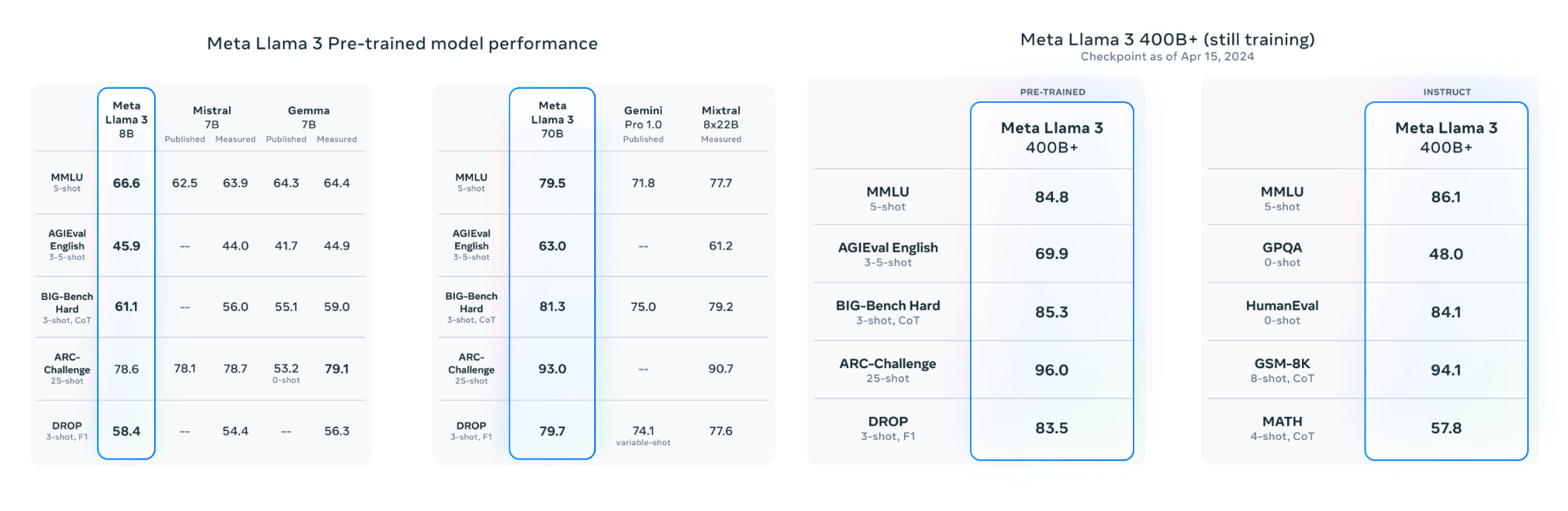
Meta’s LLama 3: The Most Capable Opensource Models 💪
Meta has finally unveiled its next generation of open-source models family Llama 3, starting with two models: 8B and 70B, available through chat via the Meta AI chatbot. The models use a new tokenizer with a vocabulary of 128K tokens that encodes language much more efficiently and improves model performance. Their context window is 8k tokens, and are trained on over 15T tokens, 7x larger than that used for Llama 2, including a significant component of non-English data. The models are the best open-source models so far for their respective sizes, with the 70B model outperforming Gemini 1.5 Pro and Claude-3 Sonnet. The largest Llama -3 model is still in training, will have over 400B parameters, multimodal, and already is at par with GPT-4 and Claude-3 Opus.
Meta is Giving Tough Competition to Gemini and ChatGPT🤖
Meta has introduced its new conversational AI, “Meta AI,” powered by Llama-3, across all its applications including Facebook, WhatsApp, and Instagram. The AI is capable of browsing the web for the latest information, generating images from text prompts, and editing or animating these images. Users can access Meta AI directly within chats, feeds, and messages on these platforms, enabling them to obtain information or recommendations without switching apps.

Which of the above AI development you are most excited about and why?
Tell us in the comments below ⬇️
That’s all for today 👋
Stay tuned for another week of innovation and discovery as AI continues to evolve at a staggering pace. Don’t miss out on the developments – join us next week for more insights into the AI revolution!
Click on the subscribe button and be part of the future, today!
📣 Spread the Word: Think your friends and colleagues should be in the know? Click the ‘Share’ button and let them join this exciting adventure into the world of AI. Sharing knowledge is the first step towards innovation!
🔗 Stay Connected: Follow us for AI updates, sneak peeks, and more. Your journey into the future of AI starts here!
Shubham Saboo - Twitter | LinkedIn ⎸ Unwind AI - Twitter | LinkedIn