
10x Faster Inference for 1M+ Context LLMs
PLUS: $600 billion AI revenue discrepancy, Waymo robotaxi gets pulled over


Today’s top AI Highlights:
Microsoft’s MInference speeds up LLM inference on long context by 10x
New Chinese opensource LLM outshines Llama 3 and Gemma 2
Waymo’s robotaxi gets pulled over by Phoenix police
AI will take center stage at Samsung’s Galaxy Unpacked event
Write code 2x faster with this AI copilot
& so much more!
Read time: 3 mins
Latest Developments 🌍
1M Context 10x Faster In A Single A100 🐎
LLM inference with long prompts faces a major computational bottleneck. The initial processing stage, called “pre-fill,” takes a lot of time, especially for prompts with millions of tokens. For instance, it could take 30 minutes for an 8 billion parameter LLM on a single A100 GPU to just handle the pre-filling of a 1 million token prompt.
Microsoft researchers have developed a new method MInference to tackle this bottleneck and speed up the pre-filling process. It analyzes and leverages patterns in how LLMs pay attention to text, making the whole process much faster without compromising the LLM’s accuracy.
Key Highlights:
Up to 10x faster - MInference makes pre-fill up to 10x faster for 1 million token prompts on a single A100 GPU. Tasks that previously took half an hour might now only take a few minutes.
Maintains or improves accuracy - MInference doesn’t just focus on speed; it maintains or even slightly improves the LLM's accuracy on different tasks.
Works with existing LLMs - You don’t need to retrain your LLM models from scratch to use MInference. It can be directly applied to existing models.
How it works - It first identifies recurring patterns in how LLMs pay attention to different parts of a text, then leverages them to optimize the pre-filling stage. To carry out the calculations needed for pre-fill, it uses specialized GPU kernels. This combination contributes to the speed gains.
Opensource LLM Built for Speed and Reasoning 🧠
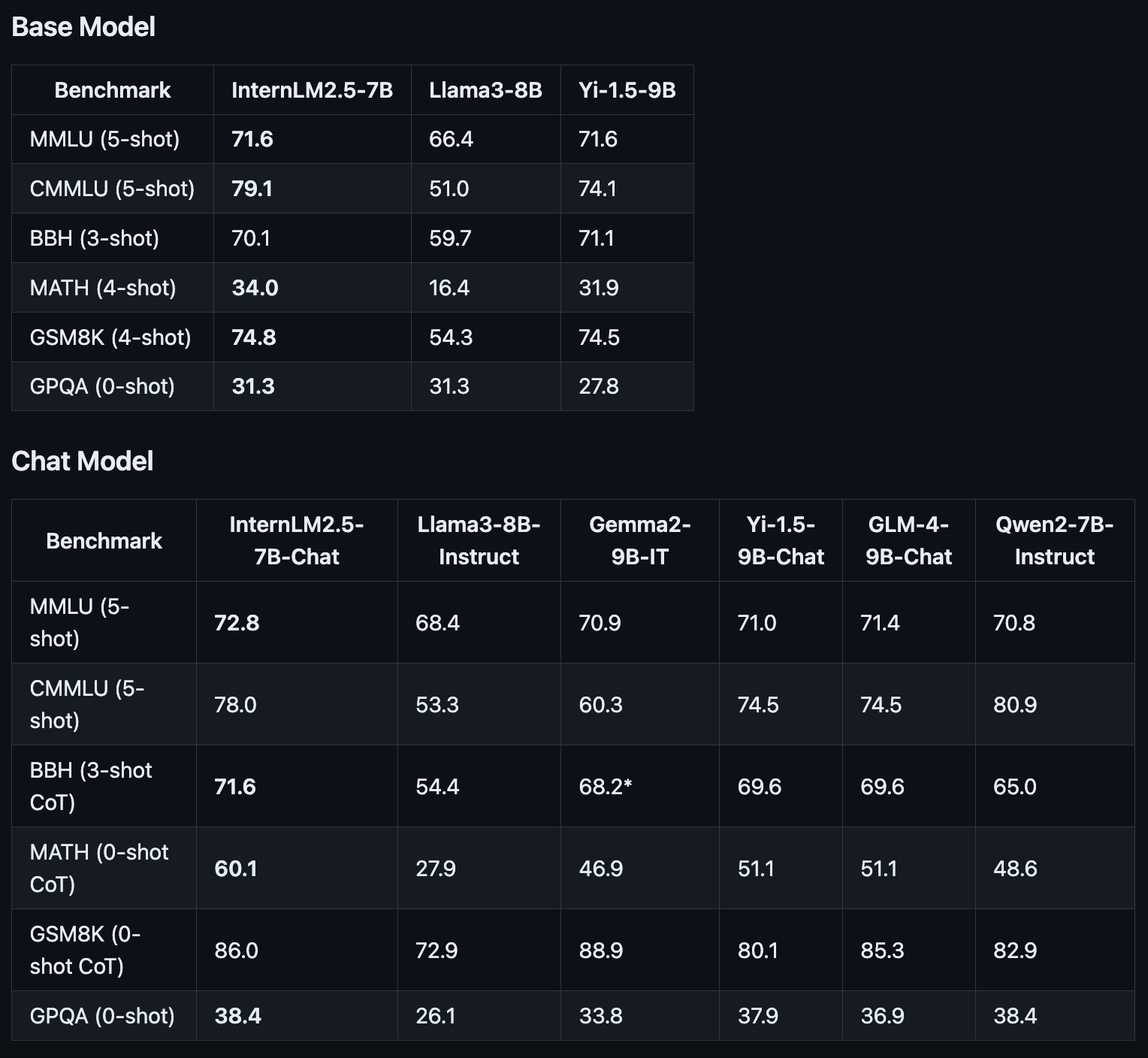
Another Chinese opensource LLM makes it to one of the best LLMs on Open LLM Leaderboard. InternLM 2.5 is designed for speed, efficiency, and enhanced reasoning capabilities. With 7B parameters, the model boasts state-of-the-art performance on complex tasks, outperforming competitors like Llama 3-8B and Gemma 2-9B. The team has also opensourced two more models, fine-tuned for instruction following, chat experience, and function call. One of them, InternLM2.5-Chat-1M, has a context window of 1 million tokens.
Key Highlights:
Outstanding Reasoning - InternLM 2.5-7B-Chat performs exceptionally well across all benchmarks including MMLU, MATH, GSM8K, and GPQA. It outperforms models in its size category like Yi 1.5-9B, Llama 3-8B, and Gemma 2-9B.
1M Context window - InternLM2.5-Chat-1M nearly perfects at finding needles in the haystack on 1 million long context, with leading performance on long-context tasks like LongBench.
Stronger tool use - InternLM2.5 supports gathering information from more than 100 web pages. InternLM2.5 has better tool utilization-related capabilities in instruction following, tool selection, and reflection.
Quick Bites 🤌
A Waymo self-driving vehicle in Phoenix got pulled over by local police. The robotaxi operating without passengers ran a red light and briefly occupied an oncoming traffic lane before parking. The vehicle was erratic moving preceding the traffic stop. While the police were unable to issue a citation to the driverless car, Waymo says the incident was due to unclear construction signage. (Source)
Samsung is heavily focusing on AI at its upcoming Galaxy Unpacked event on July 10. While current Galaxy AI features include fairly standard capabilities like on-device translation and photo editing tools, the event will be an opportunity for Samsung to unveil more unique AI functionality. Details are scarce for now, but the company is clearly aiming to make a splash in the AI space. (Source)
The AI industry is facing a revenue reality check. Seqioua says that despite predictions, the actual money generated by AI remains far below expectations, jumping from a $200 billion to a $600 billion discrepancy. While getting hold of GPUs is no longer a struggle and companies like OpenAI are seeing profits, the wider AI market isn’t seeing the same success.
Are we in a delusion thinking that “we’re all going to get rich quick, because AGI is coming tomorrow, and we all need to stockpile the only valuable resource, which is GPUs?”
😍 Enjoying so far, share it with your friends!
Tools of the Trade ⚒️
Supermaven: Fastest and free AI code completion assistant. It scans your entire codebase, making context-aware suggestions and is compatible with popular IDEs like VS Code, JetBrains, and Neovim.
BeyondPDF: Find specific phrases or keywords in your PDF documents instantly and locate related content even if you don’t know the exact wording. It runs entirely on your device so your data stays private.
Kerplunk: With this AI video interviewing tool, you can screen and interview thousands of job applicants in under three minutes, supporting 95+ languages.
Awesome LLM Apps: Build awesome LLM apps using RAG for interacting with data sources like GitHub, Gmail, PDFs, and YouTube videos through simple texts. These apps will let you retrieve information, engage in chat, and extract insights directly from content on these platforms.

Hot Takes 🔥
Sundar Pichai is the Joe Biden of AI. ~
Pedro DomingosMost of the internet will be AI APIs calling one another ~
Beff – e/accFew-shot prompting will soon become obsolete. It is just a transitional step as we shift from machine learning to LLM-centered AI. Natural interactions will win out. ~
Denny Zhou
Meme of the Day 🤡
LLMs when someone asks how many times the letter 'r' appears in 'strawberry'.

That’s all for today! See you tomorrow with more such AI-filled content.
Real-time AI Updates 🚨
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!
PS: I curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!